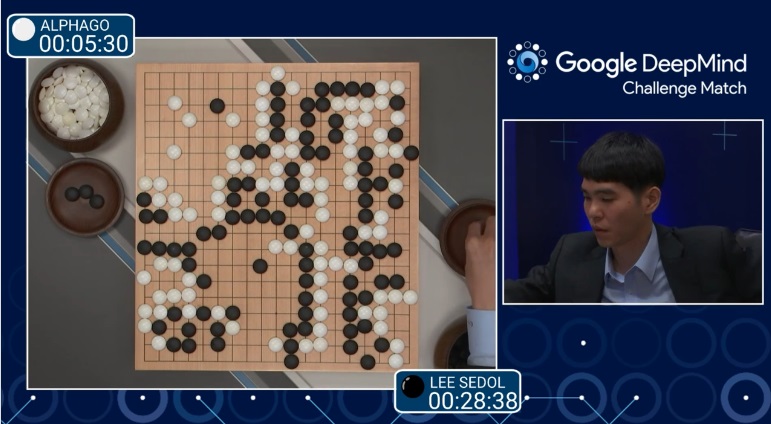
Google DeepMind tarafından geliştirilen ve Go oyununu muazzam bir biçimde iyi oynayan yapay zeka programı AlphaGo, 18 dünya şampiyonluğu bulunan efsanevi Go oyuncusu Lee Sedol’u 4-1’lik skorla mağlup etmeyi başararak hem herkesi şaşırttı hem de yapay zeka alanında önemli bir kilometre taşını devirmiş oldu.
Go oyunu var olan en eski oyunlardan biri olarak gösterilebilir ama AlphaGo ile Lee Sedol arasındaki turnuvada hayallerin ötesinde büyük bir oyun vardı ve on milyonlarca kişi bu maçı canlı olarak takip etti. Çin’de Twitter ve Facebook ‘un bir nevi benzeri ve en popüler mikroblog web sitesi olan Sina Weibo’da “Man vs. Machine Go Showdown” etiketi tam 200 milyon sayfa görüntülenmesine ulaştı. Hatta Go oyununun G.Kore’deki satışları bile yükseldi.
DeepMind, 2010 yılında kurularak bu çatı altında kendi kendine öğrenebilen bir yapay zeka yaratıldı ve bu sayede toplumun en büyük ve en acil bazı sorunlarını çözme konusunda yardımcı bir araç olarak kullanılmaya başlandı.
İnsanlığın icat ettiği en karmaşık masa oyununda makine öğrenimi ve derin öğrenmeyi temel alarak profesyonel bir oyuncuyu mağlup eden ilk yapay zeka olan AlphaGo, bu yıl 27 Ocak’ta duyurulmuştu.
Yorumcuların söylediklerine göre AlphaGo bu oyunu benzeri görülmemiş ve yaratıcı hamlelerle oynayarak kazandı.
AlphaGo, 2. oyunda bir insanın oynasa bile 10,000’de 1’lik bir şansa sahip olabileceği 37 cesur hamle gerçekleştirdi. Lee ise –10,000’de 1’lik bir şansla oynayarak– kendine özgü yenilikçi ve 78 hamle sayısı kadar hamlesiyle AlphaGo’ya karşılık vererek 4. oyunu kazandı. Oyunun skoru 4-1 AlphaGo galibiyetiyle sonuçlandı. Aynı zamanda Go oyunu ve Satranç oyunu arasındaki bazı farklılıkları da anlamak durumundayız.
Satranç oyununa başlarken her oyuncu 16 taş ile oyuna başlar. Her bir taş farklı hamlelerle hareket eder. Oyunun amacı ise rakibinizin şahını ele geçirmektir. Go oyununda ise boş bir tahta üzerinde başlanır ve her oyuncu tahta üzerine sırayla bir taş (satrançtaki taşlara eşdeğer) yerleştirir. Taşların hepsi aynı kuralı içerirler ve oyunun amacı rakibinin bölgesini olabildiğince ele geçirmektir. Go oyunun kuralları Satranç’a göre daha basit görünebilir, ancak Go oyunu çok daha karmaşık bir oyun. Go oyununda, bir oyuncunun Satranç oyununa göre olası hamle sayısı daha fazladır (Go yaklaşık 250 hamle sayısı ve Satranç 35 hamle sayısı). Oyunlar genelde uzun sürer; normal bir Go oyunu 150 hamle ve Satranç oyunu ise 80 hamle kadar sürebiliyor. Bu yüzden, Go oyununun olası toplam oyun sayısı Satranç’ın 10120 oyun sayısıyla karşılaştırıldığında, 10761 olarak tahmin ediliyor.
Evrenimizin tamamının sadece yaklaşık 1080atom içerdiği tahmin edilmesinin yanında bu iki oyun sayısı oldukça büyük sayılardır.
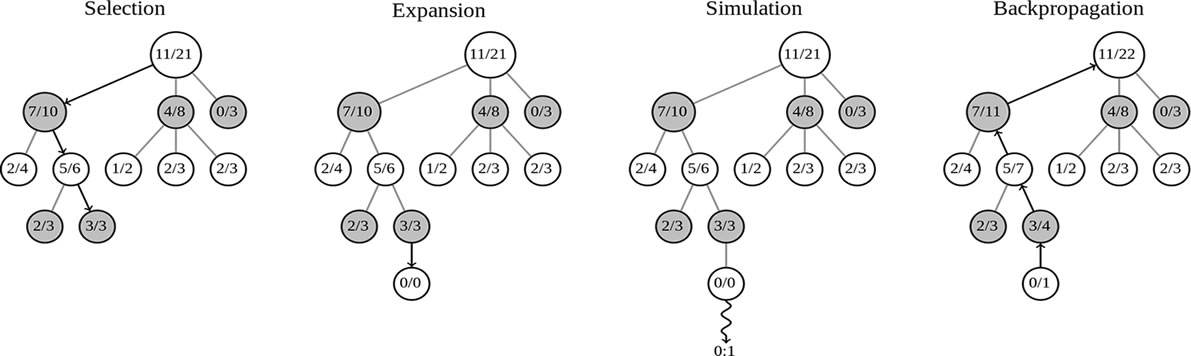
Monte Carlo Arama Ağacı
Makine öğrenme tekniği olarak derin öğrenmeyi kullanıyor olsa da 1997’de Garry Kasparovu yenmiş IBM tarafından yazılan Deep Blue programı da Monte Carlo Tree Search (MCTS) yöntemini benimsiyor. MCTS yöntemi, bir problemi daha hızlı çözmeye çalışan sezgisel arama algoritmasını kullanarak işlem yapıyor. Bu yöntem daha önce Satranç ve Üç Taş oyununda ve Go oyununda denenmişti.
Arama ağacı yöntemi hamlenin yapılacağı her bir tur için 4 farklı noktayı temel alarak sonuca gitmeye çalışıyor. Bunlar sırasıyla; Seçme – Yayılma – Taklit Etme – Geri Yayılma şeklindedir.
Başlangıç olarak bir hamle yapılmadan önce tüm hamleleri ağacın dallarına ayırıyor. Daha sonra bu dallama süreci kendini tekrar ediyor. En son elimizde dallanma süreci bitmiş bir arama ağacı duruyor. Bu ağacın her bir yaprağı ise bir hamle dizisi sonrası oluşacak bir konumu gösteriyor ve bu yapraklardaki her konum için bir skor üretiliyor, skor bilgisi ağacın yapraklarından köke doğru ilerliyor ve makine en yüksek skoru veren bir alt ağaca yöneliyor.
Kısaca Makine Öğrenimi
Makine öğrenimi, verilere dayalı öğrenimle algoritmaların tasarım ve geliştirme süreçlerini kapsayan sanat ve bilim dalına deniliyor. Amaç bir model öğrenimi için daha önce görülmemiş örnekler üzerinde genelleştirme yapabilmeyi mümkün kılmak, yani şimdiye kadar görülmemiş Go oyunları arasında sonucu doğru tahmin edebilmede iyi olabilmek.
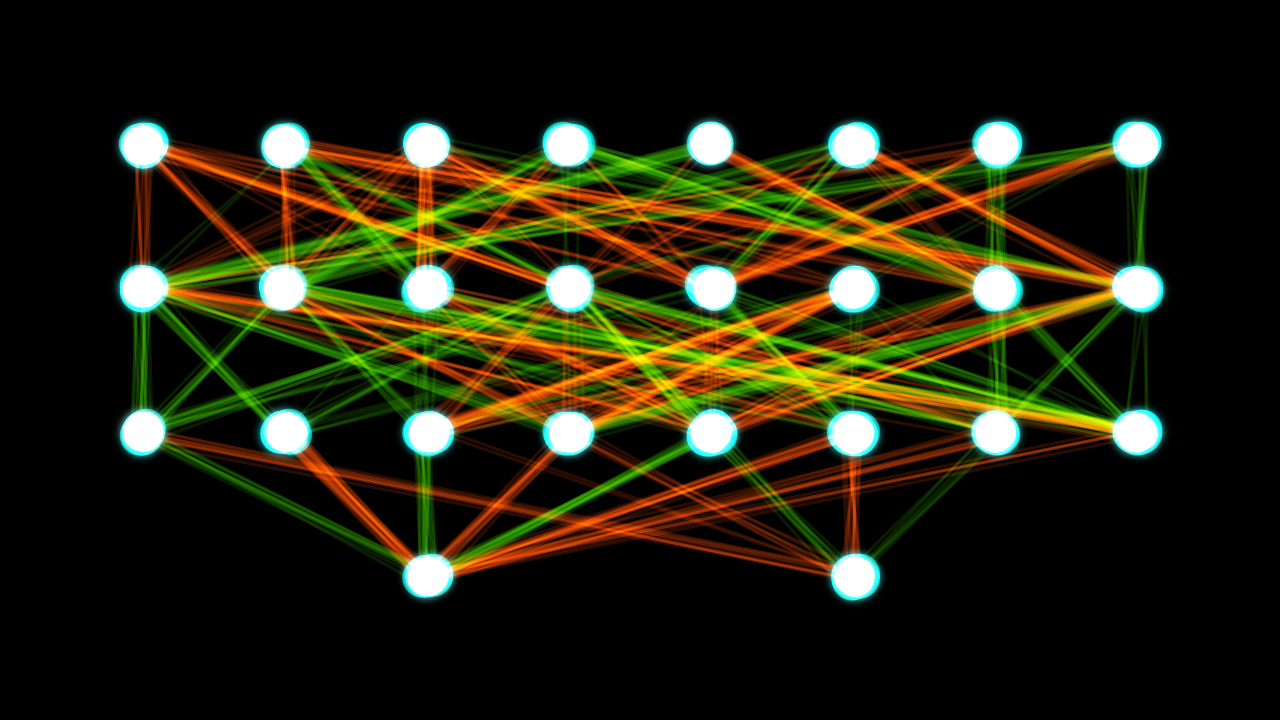
Yapay Sinir Ağları
Her bir beyaz nokta yapay bir sinir hücresi ve her bir renkli çizgi eğitilebilir bir parametreyi temsil ediyor.
Artificial neural networks (yapay sinir ağları) makine öğreniminde, denetimli ve denetimsiz ayarlamalarda, sıklıkla kullanılan modellerin bir sınıfıdır. Bu sinir ağları çok sayıda tabakadan oluşur, bunların her bir dizisini içeren parametreler bilinmeyen birer önseldir ve eğitilmeleri gerekir.
Yapay sinir ağındaki her bir katman yapay sinir hücresi içermektedir. Her sinir hücresi bir önceki katmandaki sinir hücrelerinden çıktı-veriyi girdi-veri ile ilişkilendirir. Girdi-veriler daha sonra bir arada toplanır (ve doğrusal olmayan “harekete geçirme” işlemine geçilir). Bu işlem, adının henüz nereden türediği belli olmayan “sinir” ağlarından gelen biyolojik sinir hücreleri olduğunu da hatırlatır.
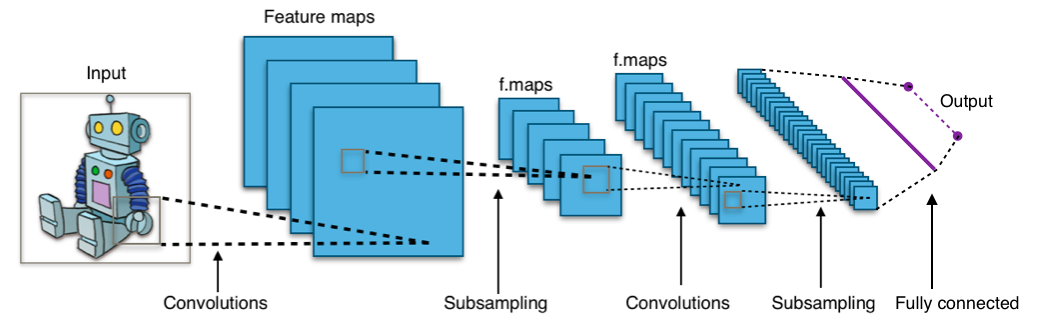
Katmanlı Ağlar
Convolutional networks (katmanlı ağlar) özellikle görsel verilerin işlenmesi için uyarlanmış ve sinir ağlarının bir alt çeşididir. Katmanlı ağlar girdi-verisi olarak bir görsel alır. Ağdaki her katmanda, görsel üzerinde bir dizi filtre uygulanır. Katmanlı ağlar görsel veriler üzerinde çok yüksek verimli bir hesaplama yaparlar çünkü kullanılabilir görsel veriler için filtreleme işlemleri sırasında kendilerini kısıtlarlar. Bu ağların yaptığı işler arasında rakam, yüz ve plaka tanıma gibi girdi-verilerinin görüntülerini çekerek her birini kendi içlerinde uygularlar. Sinir ağlarının çıktı-verisi bir dizi filtreleme işlemi sonrası elde edilir. Geri-izleme işlemi olmadan veya arama yöntemi oluşturularak uygulanırlar. Sezgisel olarak, bir görselde ki nesneleri fark eder gibi, katmanlı ağlar insanlar tarafından hızla ve sezgisel çözülebilen problemler için çok uygundur.
Nesne algılama. Katmanlı ağlar için müsait bir görev. Çoğu insanda bunu çok hızlı ve sezgisel olarak yapabilir. [Google Research]Fakat bu ağlar görseli verilmiş bir labirentin çıkışını bulabilmek gibi zaman ve derinlemesine düşünme gerektiren problemler için uygun değildirler.
Labirent içerisinde yolunu bulabilme. Katmanlı bir ağ için kolay bir engel değil; doğru yolu bulması gerekiyor. Aynı zamanda bir insanında doğru yolu bulmak için zamana ve derinlemesine düşünmeye ihtiyacı vardır.
Derin öğrenme üzerine bir not
Derin öğrenme son zamanlarda medyada çok bahsedilen bir konu. Bu terim çoğunlukla sinir ağlarının eğitimine katman katman, hırsla ve denetimsiz bir şekilde atıfta bulunur. AlphaGo tarafından kullanılan katmanlı ağlar gerçekte çok daha derindir (13 katman içerirler), ama aslında onlar katman katman değil hepsi tek seferde denetimli bir şekilde eğitilmişlerdir. Bu nedenle, açıkcası, AlphaGo derin öğrenme yöntemini kullanmaz.
AlphaGo iki farklı bileşene dayanmaktadır: arama ağacı yöntemi ve arama ağacı yönteminin kılavuzluğunu yapan katmanlı ağlar. Katmanlı ağlar kavramsal olarak biraz Deep Blue’daki değerlendirme işlevine benzerler. Arama ağacı yöntemi kaba kuvvet yaklaşımı olarak kabul edilebilir, halbuki katmanlı ağlar oyun sırasında sezgisel bir seviyeye sahiptir. Katmanlı ağlar tam olarak iki şekilde eğitiliyorlar: iki adet policy networks (politika ağı) ve bir value network (değer ağı). Bu ağların ikiside mevcut oyun sırasında girdi-verisini alır ve görsel olarak yansıtır.
Değer ağı oyun sırasında mevcut durumun değerinin bir tahminini sunar; mevcut durum göz önüne alındığında, siyah oyuncunun oyun sonunda kazanma olasılığı nedir? Değer ağında girdi-verisi oyun tahtasının bütün bölgeleridir, ve çıktı-verisi tek bir sayıdır, bu durum ise bir galibiyet olasılığı sunar. Oyunun durumu göz önüne alındığında politika ağları makinaya hangi hamleyi seçeceği konusunda yardımcı olur. Çıktı-verisi her olası hamle için olasılık değeri atar (yani ağın çıktı-verisi oyunun tahtası kadar geniştir). Yüksek olasılık değerli hamleler oyunu kazanmak için daha yüksek bir şansa sahip hamlelere karşılık gelir. Bir politika ağı KGS Go sunucusunda yer alan amatör ve profesyonel oyunları kullanarak bir insan tarafından 30 milyon durum üzerinde eğitiliyor. Bir test dizisi üzerinde %57 doğruluk payı elde edildiği görülmüştür. Küçük bir politika ağı daha iyi bir şekilde eğitiliyor, doğruluk olasılığı daha düşük oluyor olsa da (%24.2), daha hızlı olduğu gerçeğini yansıtıyor (3 milisaniye yerine 2 mikrosaniye: 1500 kez daha hızlı).
AlphaGo ne kadar iyi?
AlphaGo ne kadar iyi? AlphaGo diğer insanlar ve yapay zekalarla karşılaştırıldığında ne kadar güçlüdür sizce? Oyuncuların gücünü karşılaştırmak için kullanılan en yaygın sistem Elo derecelendirme sistemidir. Kazanma şansının hangi tarafa göre daha yüksek olduğu derecelendirmelerde, bir müsabakanın sonunda iki oyuncu arasındaki puan farkının derecelendirilmesini sağlayan bir sistemdir. 2015’te birçok yapay zekanın gücü aşağıdaki gibi tahmin edildi:
Yapay Zeka adı
Elo derecelendirmesi
Distributed AlphaGo (2015)
3140
AlphaGo (2015)
2890
CrazyStone
1929
Zen
1888
Pachi
1298
Fuego
1148
GnuGo
431
AlphaGo’nun standart sürümü 48 işlemci ve 8 grafik kartı kullanırken, yaygın sürümü 1202 işlemci ve 176 grafik kartı kullanıyor.
Ne yazık ki, tek bir işlemci kullanan AlphaGo, Elo derecelendirmesini hesaplayamamıştı, fakat AlphaGo’nun yaygın sürümü ünlü Go oyuncusu Fan Hui karşısında beş maçın hepsini kazanmayı başarmıştı. Fan Hui, Elo sisteminin hesaplarına göre 2,908 gibi bir puan alan 2 dan ünvanına sahip profesyonel bir oyuncu.
15 Mart 2016’da, AlphaGo’nun yaygın versiyonu Lee Sedol karşısında 4-1 kazanarak Elo derecelendirme sistemine göre puanı 3,520 olarak hesaplandı. AlphaGo’nun şuanki yaygın versiyonu tam olarak 3,584 puanda. Eğer makine 2015 yılından bu yana geliştiriliyor olmasaydı muhtemelen Lee Sedol karşısında kazanma olasılığı olmayacaktı. AlphaGo’dan daha yüksek bir Elo derecelendirmesine sahip tek kişi ise şuan 3615 puanla genç Go oyuncusu Ke Jie.
Sırada ne var?
DeepMind ekibi bir sonraki yapay zeka mücadelesinde ne üzerinde çalışacak? Bunun cevabını verebilmek biraz zor. Bilgisayar oyunu oynayabilen yapay zekanın karmaşık bir yapıya sahip olması yüzünden ilginç engellerle karşılaşacağı kesin.
Aslını söylemek gerekirse, DeepMind hali hazırda kendileri yapay zekaya Atari oyunları oynamayı öğretmişlerdi. Bilgisayar oyunu oynayabilen yapay zekanın bu nedenle sonraki engelini kolay bir şekilde ele alacağı gözüküyor.
Bu web sayfası sizlere en iyi kullanıcı tecrübesini sunmamız adına çerezler kullanmaktadır. Çerez bilgileri tarayıcınızda saklanır ve bize sayfamıza geri döndüğünüzde sizi fark etmemizi ve en çok hangi içeriğe ilgi duyduğunuzu anlamamızı sağlar.
Kesinlikle gerekli çerezler
Çerez ayarları tercihlerinizi kaydedebilmemiz için kesinlikle gerekli çerezler her zaman etkin olmalıdır.
Bu çerezi devre dışı bırakırsanız, tercihlerinizi kaydedemeyiz. Bu da, bu web sitesini her ziyaret ettiğinizde çerezleri tekrar etkinleştirmeniz veya devre dışı bırakmanız gerekeceği anlamına gelir.




![[Nature]](https://www.dijitalx.com/wp-content/uploads/2016/03/policy-value-networks.png)
{kind=link}